概要|Pythonでかっこいい折れ線グラフ(散布図)を作っていく
こんにちは、すのくろです。
今回は、csvのような表データから、平均値と標準偏差を計算して簡単に折れ線グラフ(散布図)にする方法について記載します。
<概要>
表データを集計して、代表値(今回は各列の平均値と標準偏差)を時系列の折れ線グラフ(散布図)でまとめる方法を紹介
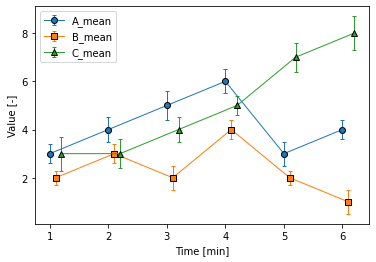
以下のようなものが最終アウトプットです。
それでは解説していきます!
必要なモジュールのインポート & csvデータの読み込み
はじめに、データの操作・計算やグラフ描画をしていくために、必要なモジュール(関数を使うためのパックみたいなもの)をインポートします。
import pandas as pd
# import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline続いて、扱いたいデータを読み込みます。
今回は「plot_data.csv」という3個の指標(A, B, C)の平均値とそのばらつき(標準偏差)を6回の時間ごとにまとめた表を想定しています。
以下に、これから用いるcsvファイルの作成プログラムとそのイメージ図を置いておきます。
# データ作成プログラム
# 平均値
a = [3, 4, 5, 6, 3, 4]
b = [2, 3, 2, 4, 2, 1]
c = [3, 3, 4, 5, 7, 8]
# 標準偏差
aa = [0.4, 0.5, 0.6, 0.5, 0.5, 0.4]
bb = [0.3, 0.4, 0.5, 0.4, 0.3, 0.5]
cc = [0.7, 0.6, 0.5, 0.4, 0.6, 0.7]
# 時間
t = np.arange(1, 7)
df = pd.DataFrame({"Time": t, "A_mean": a, "B_mean": b, "C_mean": c, "A_sd": aa, "B_sd": bb, "C_sd": cc})
df.to_csv("plot_data.csv") 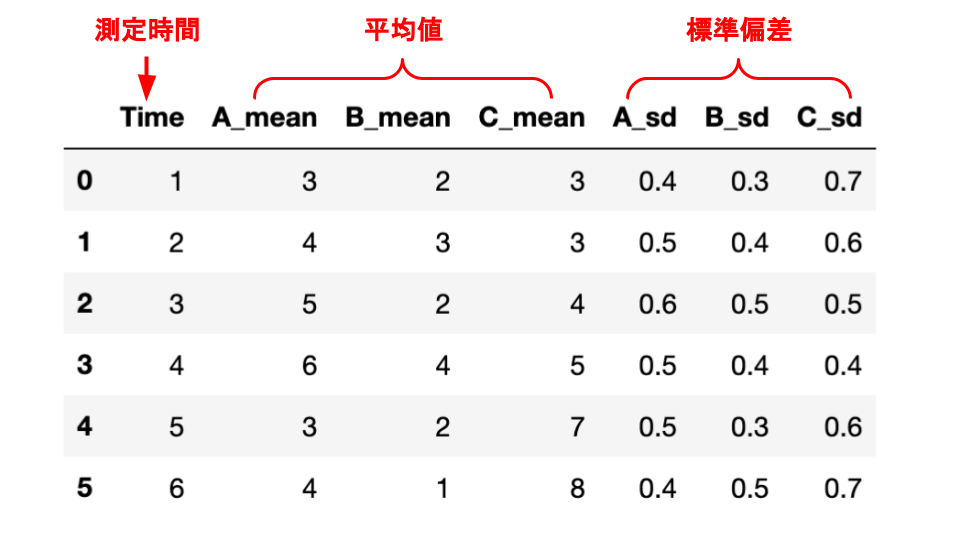
「plot_data.csv」を読み込むのが以下のコードです。
この辺りは基本なので、もし心配な方がいたら以前の記事にも同じ手順が書いてあるので参考にして学んでみてください!
# このファイルと同じフォルダに入っているcsvの表データファイルの読み込み
df = pd.read_csv('plot_data.csv')
df折れ線グラフの作成(単一データ)
それでは、データが読み込めた所で、主題の折れ線グラフ作成に移りましょう。
コードは下記です。
x = df["Time"] #表データの”Time"列をx軸に
y = df["A_mean"] #表データの”AAA"列をy軸に
plt.plot(x, y) #plt.plot()で散布図の描画実行結果がこちらです。
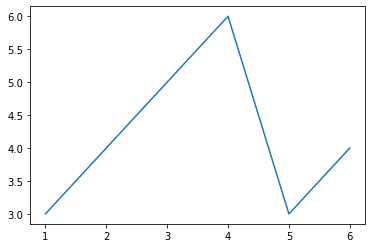
折れ線グラフ(厳密には散布図)はxとyの同じ個数のデータを「plt.plot(x, y)」のように与えてあげるだけでできます。
今回のxは表dfの1番左の列の「Time」列を指定しています。
yは表dfの2番目の列の「A_mean」(項目「A」の平均値)です。
折れ線グラフの作成(複数データ)
続いて、複数のデータを一つのグラフに表す方法について説明します。
答えを言うと、「plt.plot()」を連続で書いちゃえばOKです!
以下がその例です。
# データ数増やす場合
x = df["Time"] #表データの”Time"列をx軸に
y1 = df["A_mean"] #表データの”AAA"列をy軸に
y2 = df["B_mean"]
y3 = df["C_mean"]
plt.plot(x, y1) #plt.plot()で散布図の描画
plt.plot(x, y2)
plt.plot(x, y3)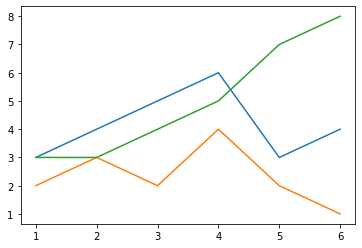
「plt.plot()」を複数書いて、その中の引数(xとかyとか)を変えてあげるだけで、単一窓に表示されます。
もう少しpythonに慣れてくると、「繰り返して何度もyとかplt.plot()書くの面倒くさいな」と思うかと思います。
(既に思っている方もいるかと思います。)
そんなときは、「for」文でループ処理をしてあげればいいんです!
以下が、「for」文を使って簡潔にしたコードになります。
# for文でまとめて行うこともできる
x = df["Time"] # 表データの”Time"列をx軸に
for i in range(3): # 「1、2、3」という変数を順に渡す
y = df.iloc[:, i+1] # 表dfの中で、全ての行の、i+1番目の列のデータを取得
plt.plot(x, y) # plt.plot()で散布図の描画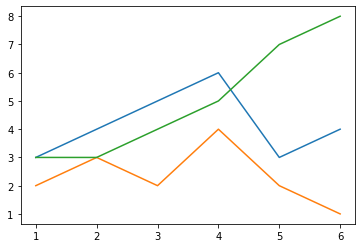
先ほどと同じグラフが出力されているのがわかるかと思います。
for内部に、繰り返し書きたい
・「y」の値
・そのyとxを使った「plt.plot()」
を入れてあります。
このコードを参考にしてもらえれば、どれだけデータの項目数が増えても一発で折れ線グラフが書けます!!
装飾
ある程度、折れ線グラフ(散布図)の作成のコツが掴めてきた所で、グラフの完成度を上げていきます。
グラフの装飾は本当にたくさんあるため、各自調べて好きなように変更してもらえれば幸いです。
今回は、以下を追加しました。
・凡例
・x軸名
・y軸名
・マーカー
# 凡例や軸、マーカーなどの装飾の追加
x = df["Time"]
name = df.columns #凡例用に表の列名を取得
for i in range(3): # 「1、2、3」という変数を順に渡す
y = df.iloc[:, i+1] # 表dfの中で、全ての行の、i+1番目の列のデータを取得
plt.plot(x, y, label=name[i+1], marker="o") # plt.plot()で散布図の描画、「label」引数で、凡例名を指定
plt.legend() #凡例を表示
plt.xlabel('Time [min]')
plt.ylabel('Value [-]')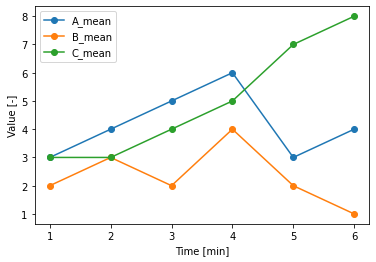
エラーバーの追加
次に、平均値のような代表値をグラフで表現する以外に、分散として標準偏差をグラフに追加したいと思います。
エラーバーをつけるときには「plt.errorbar()」を使ってグラフを作成します。
(関数の名前がそのままなので、分かりやすいですね。笑)
「plt.errorbar(x, y, yerr)」
xとyに関しては、今までと同じく使いたいx, y座標の値です。
さらに、新たな引数として「yerr」があります。
yerrに標準偏差などのばらつきの値を指定してあげれば完成です。
以下が参考コードです。
x = df["Time"]
y = df.iloc[:, 1]
e = df.iloc[:, 4] #dfの5列目(Aの標準偏差)の取得
# エラーバーをつけるときは、plt.errorbar()
plt.errorbar(x, y, yerr=e, marker="o", label = "A", capthick=1, capsize=2, lw=1)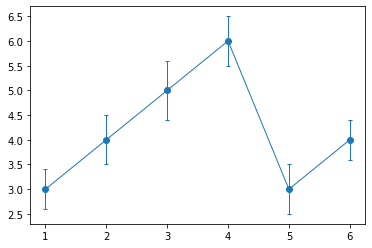
今回は、表データdf(plot_data.csv)の5〜7列を事前に項目A, B, Cの標準偏差として準備していました。
なので、e = df.iloc[:, 4]
として、表dfの5列目(Aの標準偏差)を取得して、yerr=eとしてplt.errorbar()内に指定してあげてます。
他の引数としては、「capthick」と「capsize」が追加されています。
「capthick」とは、エラーバーの線の太さです・
「capsize」というのはエラーバーの上端と下端の幅の大きさです。
「plt.errorbar()」についてわかってきた所で、複数データでもfor文で行ってみましょう。
と言っても、先ほどfor文のコードの「plt.plot()」を「plt.errorbar()」に変更して、少し情報を付け加えただけです。
以下のコードです。
# for文で3列分のデータを回す場合
x = df["Time"]
name = df.columns #凡例用に表の列名を取得
for i in range(3): # 「1、2、3」という変数を順に渡す
y = df.iloc[:, i+1] # 表dfの中で、全ての行の、i+1番目の列のデータを取得
e = df.iloc[:, i+4] # 表dfの中で、全ての行の、i+4番目の列のデータを取得
plt.errorbar(x, y, yerr=e, label=name[i+1], marker="o", mec="k", capthick=1, capsize=2, lw=1)
plt.legend() #凡例を表示
plt.xlabel('Time [min]')
plt.ylabel('Value [-]')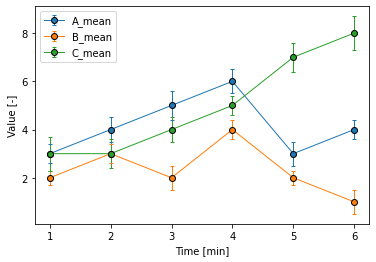
エラーバーの追加2(エラーバーをずらす)
ここまでで、ほとんどメインの話は終わりです。
最後に、エラーバーをずらして、エラーバー同士の重なりがなくなるような工夫だけ紹介します。
完成図は下記のグラフです。
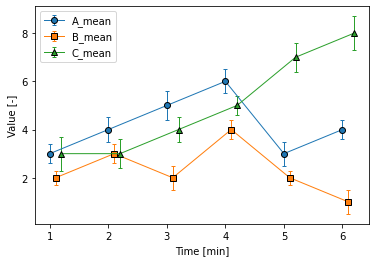
この図だと、Timeが1、2の時、今まで重なっていたマーカーやエラーバーがずれて、少し見やすくなっているかと思います!
具体的な方法としては、データによって散布図のx座標を少しずらしてあげているだけです。
以下が、そのコードです。
# x軸ずらす場合
x = df["Time"]
name = df.columns #凡例用に表の列名を取得
marker_list = ["o", "s", "^"] #マーカーの形のリスト(丸、四角、三角)を作成
for i in range(3): # 「1、2、3」という変数を順に渡す
y = df.iloc[:, i+1] # 表dfの中で、全ての行の、i+1番目の列のデータを取得
e = df.iloc[:, i+4] # 表dfの中で、全ての行の、i+4番目の列のデータを取得
plt.errorbar(x, y, yerr=e, label=name[i+1], marker=marker_list[i], mec="k", capthick=1, capsize=2, lw=1)
plt.legend() #凡例を表示
plt.xlabel('Time [min]')
plt.ylabel('Value [-]')
x = x+0.1 # 次の繰り返し時にx軸の値を右に少しずらすfor文の最後に
「x = x+0.1」
が入っていますが、この1行で次の繰り返し時にx座標が+0.1されているので、データが重ならないという仕組みです。
それだけです。
あとは、しれっとマーカーの形を変えました。
marker_list = [“o”, “s”, “^”]
で、マーカーの形(丸、四角、三角)の指定のリストを作り、引数marker=marker_listで指定してあげてます。
これでより、データの区別がしやすいですね。
まだ他にも、改良の余地があるかと思いますが、今回はここまでとします。
十分見やすい折れ線グラフになったのではないでしょうか。
まとめ
- plt.plot()で折れ線グラフの作成
- plt.errorbar()でエラーバー付き折れ線の作成
- xを少しずつずらすことも可能
他にも本ブログでは、グラフの見栄えを良くする方法について解説したりしています。
参考になれば幸いです。
グラフ関連記事(グラフの装飾のデフォルト設定を変更する方法)
また、他にもpythonを使ったグラフを臨機応変に作りたいという方におすすめなのが、やはり検索性の高い紙媒体の書籍となります。
私が参考にしたおすすめ書籍は下記のものです。
正直、少しお高いですが、この手の書籍を一冊持って手元に置いておくと、すぐにpythonの作業が進むので時間対効果は高いのかなと自分は感じています。是非購入して頂ければ幸いです。
以上長くなりましたが、今回はこの辺りで終えたいと思います。
Pythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
以上、ここまでお読みいただき、ありがとうございました!

コメント