概要
こんにちは、すのくろです。
今回は、Pandasによる表データ(データフレーム)から、ある行や列のデータから、グループ別に値を算出する方法について説明します。
具体的には「df.groupby()」を使った方法の解説になります。
本記事の内容は次のとおりです。
- df.groupby() の使い方
- df.groupby().describe()で、グループ別の統計量の取得
- df.groupby().describe()[ “列名” ]で、ある列のグループ別の統計量の取得
- ある列のグループ別の特定の統計量の取得
今回の記事を学ぶことで、瞬時に好きなデータのグループ別の値を簡単かつ直感的に取得して、後のグラフ作成の算出ができるようになります!
それでは、やっていきましょう!
データフレームの作成
初めに今回用いるデータフレーム(df)を作成していきます。
コードは下記の通りです。
data = {
"name": ["Abe", "Ito", "Ueda", "Endo", "Okamura",
"Kato", "Sato", "Tanaka", "Nakamura", "Hamada"],
"age": [22, 30, 32, 20, 40, 11, 23, 45, 56, 46],
"sex": ['male', 'male', 'female', 'male', 'female',
'male', 'female', 'male', 'female', 'female'],
"height": [160, 170, 158, 178, 173, 165, 156, 175, 145, 160],
"weight": [65, 66, 46, 77, 70, 45, 55, 67, 68, 77]
}
df = pd.DataFrame(data)
df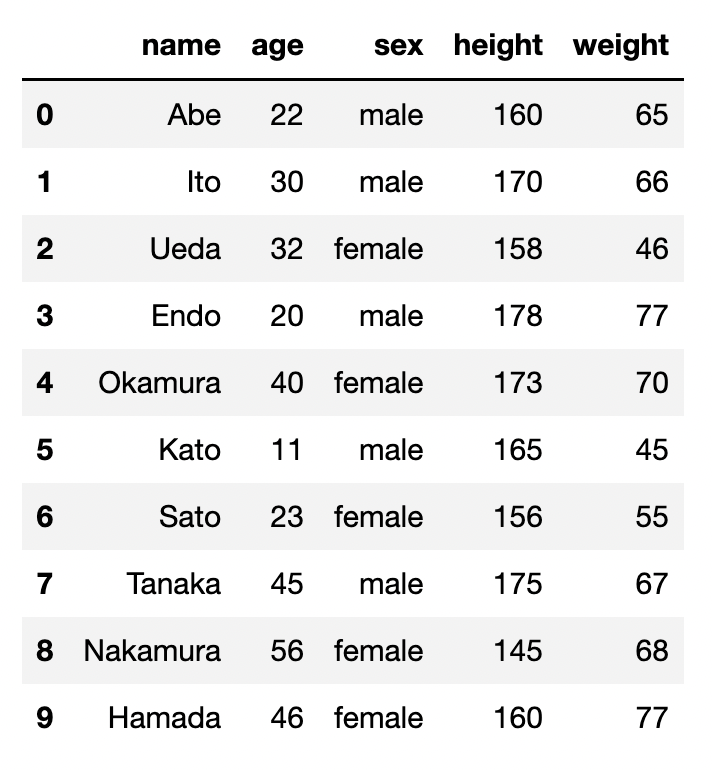
こちらは10名の方の名前、年齢、性別、身長、体重がまとめられた表になっています。
今回はこちらのdfを使って色々と表を操作していきます。
df.groupby() の使い方
まず初めに、dfの「.groupby()」の仕組みについて解説していきます。
df.groupby("列名")とすることで、その指定列で自動で項目ごとに値をグループ分けしてくれます。
ただ上記コードだけではグループ別に分けるだけで何も起きず、基本的には、「df.groupby()」+ 「他の関数」でセットで使います。
例えば、下記のコードです。
# 各グループごとに平均値などを出せる
# 男女別の平均値
df.groupby("sex").mean()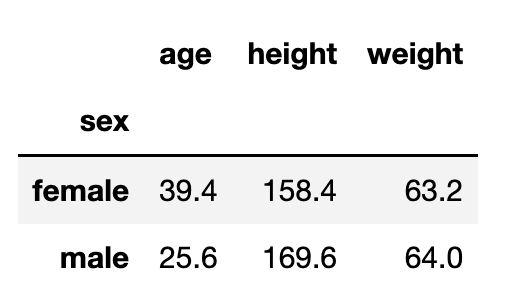
このように、今回はdfの中の列「性別(sex)」で男女別(male/ female)の平均値を簡単に算出することができました。
注意点としては、平均値のような統計量は数字しか出せないので、もし列のデータの型が文字の場合は省略されて出てこないことがあげられます。
df.groupby().describe()で、グループ別の統計量の取得
次に、.groupby()と.describe()を組み合わせた統計量の算出方法について説明していきます。
下記コードで、一気にグループ別の統計量を取得することができます。
# describe()で統計量を一気に見れる
df.groupby("sex").describe()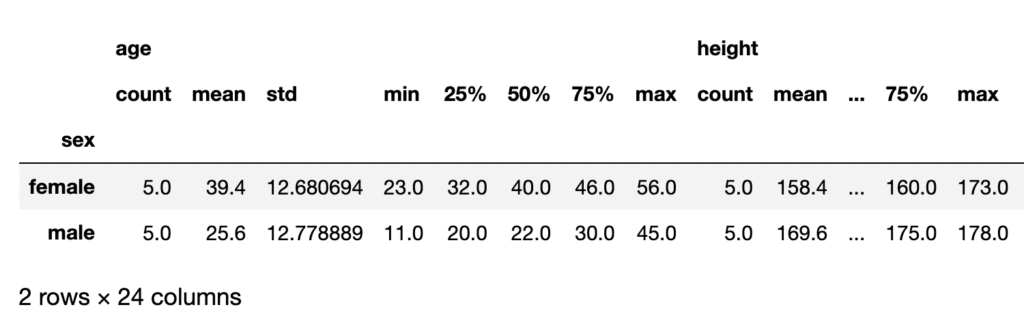
ただ、これだと全ての列に対して、平均値や最大値、中央値などの各種統計量がでてしまい、見にくいです。
そこで、欲しい項目(列名)だけを一つだけ出力する方法を下記コードで行います。
# 男女別の体重"weight"の統計量のみ抽出
weight_data = df.groupby("sex").describe()["weight"]
weight_data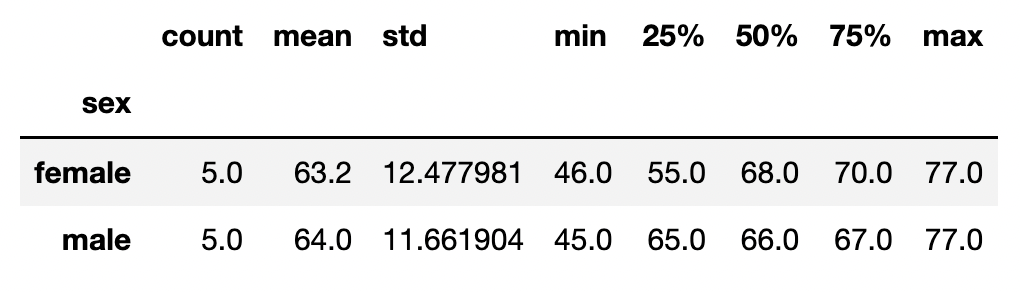
.describe()の後に続けて列名[“weight”]で指定してあげることによって、
weight列だけの統計量を取得しています。
さらに、例えば列名[“weight”]の統計量の中で、平均値(mean)だけが欲しい場合は下記のように限定します。
weight_data["mean"]
# (df.groupby("sex").describe()["weight"]["mean"] でも可能)
###
# sex
# female 63.2
# male 64.0
# Name: mean, dtype: float64この辺りの知識は、他の記事で解説した内容とも関連があるためそちらも合わせてお読み頂ければ幸いです。
まとめ
今回は、Pandasによる表データ(データフレーム)から「df.groupby()」を使って、ある行や列のデータからグループ別に値を算出する方法について説明しました。
まとめると本記事の内容は次のとおりです。
- df.groupby() の使い方
- df.groupby().describe()で、グループ別の統計量の取得
- df.groupby().describe()[ “列名” ]で、ある列のグループ別の統計量の取得
- ある列のグループ別の特定の統計量の取得
「df.groupby()」を利用することで、瞬時に好きなデータのグループ別の値を簡単に取得して、後のグラフ作成の算出ができるようになることがわかってもらえたらと思います!
Pythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
以上、ここまでお読みいただき、ありがとうございました!


コメント