
こんにちは、すのくろです。
本日はPythonを使ったデータ分析に興味を持ってる方向けに、
膨大な量のCSVファイルを一気にデータフレームにまとめる方法をお伝えします。
この方法を覚えれば、たくさんファイルを集めた時にも慌てず効率的にデータをまとめて処理して行けるようになると思います!
それではやっていきましょう。
ライブラリのインポート
Pythonプログラムで使用するライブラリをインポートします。
import os
import time
import numpy as np
import pandas as pd- os:OS依存の機能を利用するためのライブラリ
- time:時間に関する操作を行うためのライブラリ
- numpy:数値計算用ライブラリ
- pandas:データフレームを操作するためのライブラリ
CSVファイルの作成

続いて、データ操作用のCSVファイルのデータを適当に作っていきます。
今回は、ランダムなデータを含むCSVファイルを生成してみます。
100行2列のデータと、時刻データを含めてCSVファイルを作成してみます。
CSVファイルを30個作成して、「csv_data」というフォルダの中に
コードの例は下記になります。
for num in range(1, 31):
# 100行2列のランダムなデータを生成する
data = np.random.randn(100, 2)
# 1秒ごとの時刻を追加する
time_col = []
current_time = time.time()
for i in range(100):
time_col.append(current_time)
current_time += 1
# 時刻データを最初の列に挿入する
data = np.insert(data, 0, time_col, axis=1)
# データフレームに変換する
df = pd.DataFrame(data, columns=['Time', 'A', 'B'])
# 時刻を年、月、日、時間の形式に変換する
df['Time'] = pd.to_datetime(df['Time'], unit='s').dt.strftime('%Y-%m-%d %H:%M:%S')
# データをCSVファイルとして保存する
df.to_csv('csv_data/data_{}.csv'.format(num), index=False)
- range(1,31):forループで1から30までの数値を処理するためのリストを生成する。
- np.random.randn(100, 2):100行2列のランダムなデータを作成する。
- time.time():現在時刻を秒単位で取得する。
- pd.to_datetime():pandasのto_datetimeメソッドを使って、Unix時間を年月日時分秒に変換する。
- dt.strftime():pandasのstrftimeメソッドを使って、指定した形式の文字列に変換する。
- df.to_csv():pandasのto_csvメソッドを使って、データフレームをCSVファイルとして保存する。
できたファイルは下記のようなCSVファイルです。
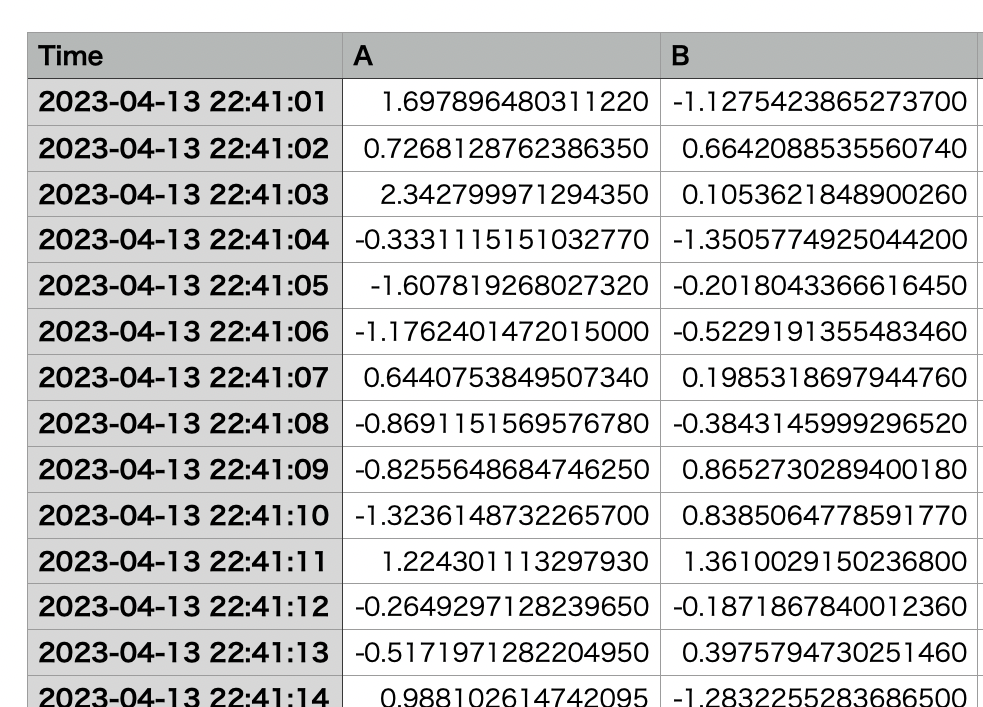
同様の構造のファイルを今回30個生成しました。
これらの複数のファイルをすべて一括でまとめていきます!
データを一つのCSVファイルに集約
ここから本題の複数のCSVファイルを1つのファイルにまとめる方法について解説していきます。
CSVファイルが保存されたフォルダのパスを指定
まず、csv_dataフォルダ内に保存されたCSVファイルを一つにまとめます。
osモジュールを使ってCSVファイルが保存されたフォルダのパスを指定します。
# csvファイルが入っているフォルダのパスを指定
csv_dir = 'csv_data'
今回対象のファイルが入っているフォルダ名を指定します。
今回はフォルダ名のみで書いていて、対象フォルダとこのプログラムが同じディレクトリ(場所)にある前提で相対パスで書いています。
フォルダ内のファイル名をリストで取得
次に、os.listdir関数を使って、フォルダ内のファイル名をリストで取得します。
コードは下記です。
# フォルダ内のファイル名を読み込み
csv_files = os.listdir(csv_dir)
# フォルダ名もつけてパスを生成
csv_files = [os.path.join(csv_dir, f) for f in csv_files if f.endswith('.csv')]
# 並び替え
csv_files.sort()
簡単にやってることを解説します。
forループを使って、CSVファイルのパスをリストで生成しています。
この時、フォルダ内にCSVファイル以外のファイルが存在する場合に備えて、if文で'csv'で終わるファイルのみを処理対象に指定します。
また、os.path.join関数を使って、フォルダ名もつけたファイルのパスを生成しておきます。
このファイルのパス名を今後指定して、ファイルを操作していきます!
CSVファイルに保存されているデータを一つにまとめる
例①.元のファイルの列名のまま結合
次に、pd.concat関数を使って、CSVファイルに保存されているデータを一つにまとめます。
# データを一つのcsvファイルに集約
dfs = []
for f in csv_files:
df = pd.read_csv(f)
dfs.append(df)
df_merged = pd.concat(dfs, axis=1)
df_merged.to_csv('all_data_01.csv', index=False)
ここでは、
dfsという空のリストを用意します。csv_filesに含まれるCSVファイルを1つずつ読み込み、pd.read_csv()関数でデータフレームとして読み込んでいます。このとき、pd.read_csv()関数の引数には、ファイル名を指定しています。- 読み込んだデータフレームを、
dfsリストに追加しています。 pd.concat()関数を使って、dfsリストに含まれるデータフレームを列方向に連結しています。具体的には、pd.concat(dfs, axis=1)という形で、dfsリストに含まれるデータフレームを横方向に結合しています。結合されたデータフレームは、df_mergedという変数に代入されます。df_merged.to_csv()関数を使って、結合されたデータフレームをCSVファイルとして保存しています。保存するファイル名はall_data_01.csvで、インデックスを除外するために、index=Falseの引数が指定されています。
できたファイルの中身
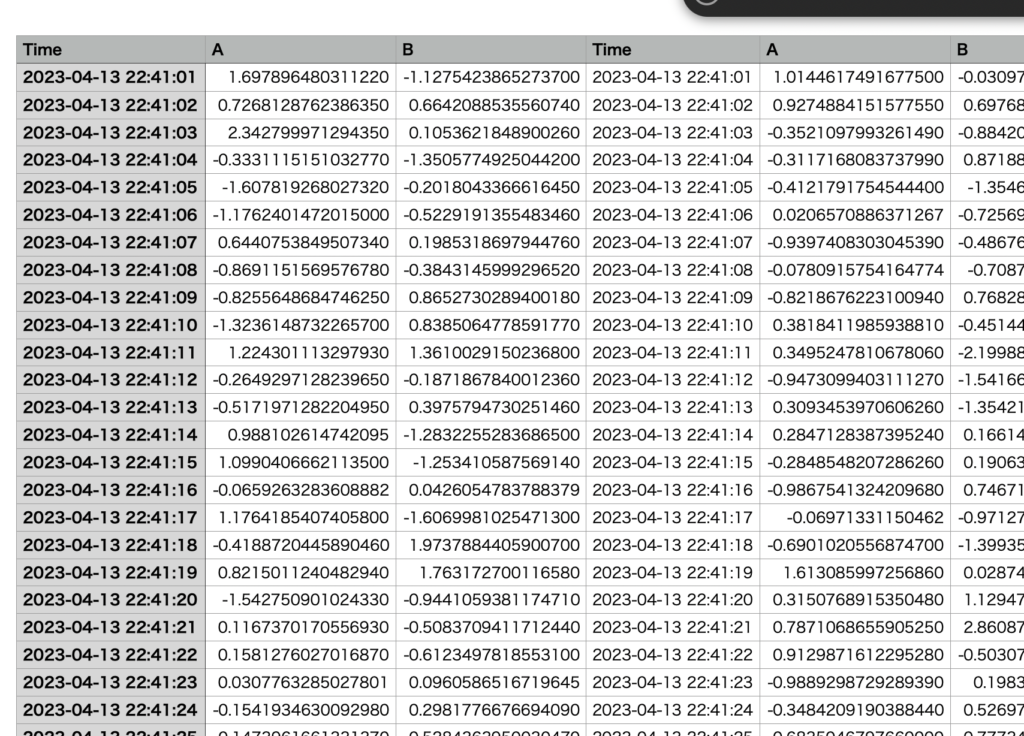
横に複数のデータがまとまっていることがわかると思います。
例②.列名を数字の連番に変更
次に、CSVファイルに保存されたデータフレームの列名を数字の連番に変更します。
まず、pd.concat関数の引数にignore_index=Trueを指定することで、列名を再度設定しなくても、自動的に連番の列名が設定されます。
そして、df_merged.to_csvメソッドを使って、all_data_02.csvというファイル名でCSVファイルを保存します。
中身は下記のようになります。列名がただの数字の連番になっていることがわかります。
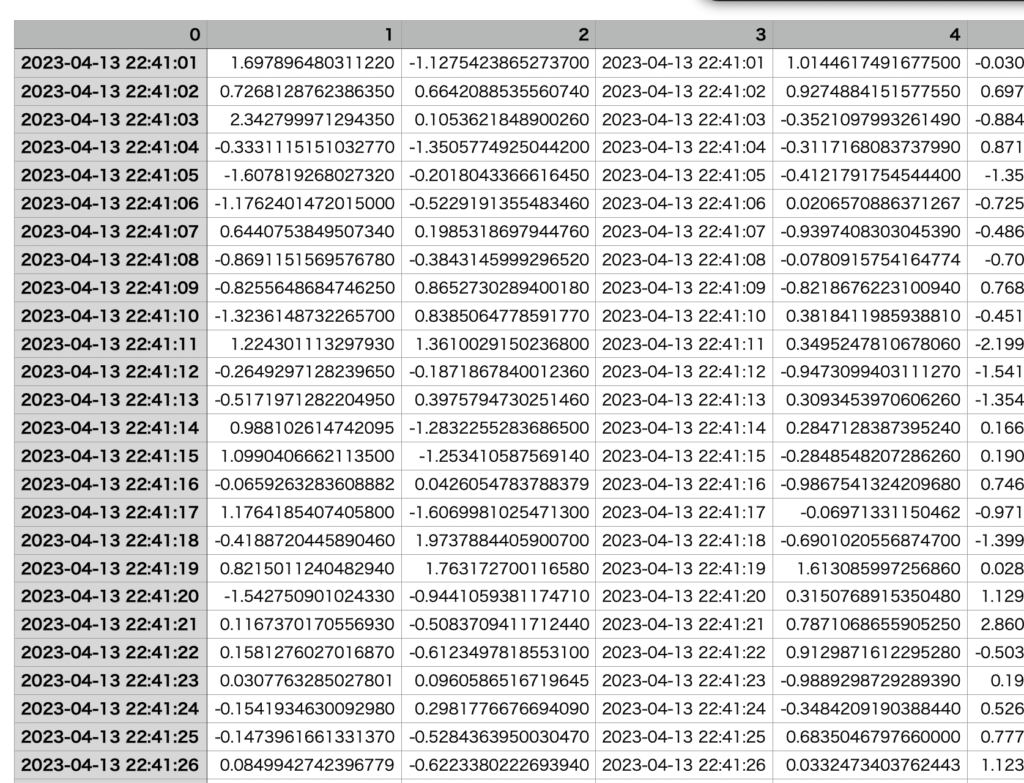
例③.列名にファイル番号を追加
例①、②では、簡単にファイルを列方向にまとめることができましたが、どのファイルのデータをとって順番に並んでいるのか分からない状態です。
そこで、少しプログラムを改良して元のファイルの名前を列名に付け加えて集約する方法に変更します。
# 列名にファイル番号を追加
dfs = []
for f in csv_files:
df = pd.read_csv(f)
df = df.rename(columns={col: col + '{}'.format(f[13:-4]) for col in df.columns})
dfs.append(df)
df_merged = pd.concat(dfs, axis=1)
df_merged.to_csv('all_data_03.csv', index=False)変更点は、フォルダ内にあるCSVファイルのリストを取得しているforループ内の箇所です。
それぞれのファイルに対してファイル名を取得して列名の末尾に追加していることです。
具体的には下記の操作です。
- renameメソッドを使って、各列の名前にファイル名から取得したファイル番号を追加
- ファイル番号は、ファイル名から取得した文字列の一部(今回は連番番号部分)を切り出して、列名の末尾に追加
参考は下記です。ファイル名文字列「f」に対して、スライシングを行い、「_9」のように抜き出して、列名末尾に付け加えています。

最後に、pd.concat関数を使ってdfsリスト内のデータフレームを結合し、1つのデータフレームにまとめます。
結合する際には、axis=1を指定して列方向に結合します。結合されたデータフレームは、all_data_03.csvという名前のCSVファイルに保存されます。
最終的にできた集約されたファイルの中身は以下の通りです。
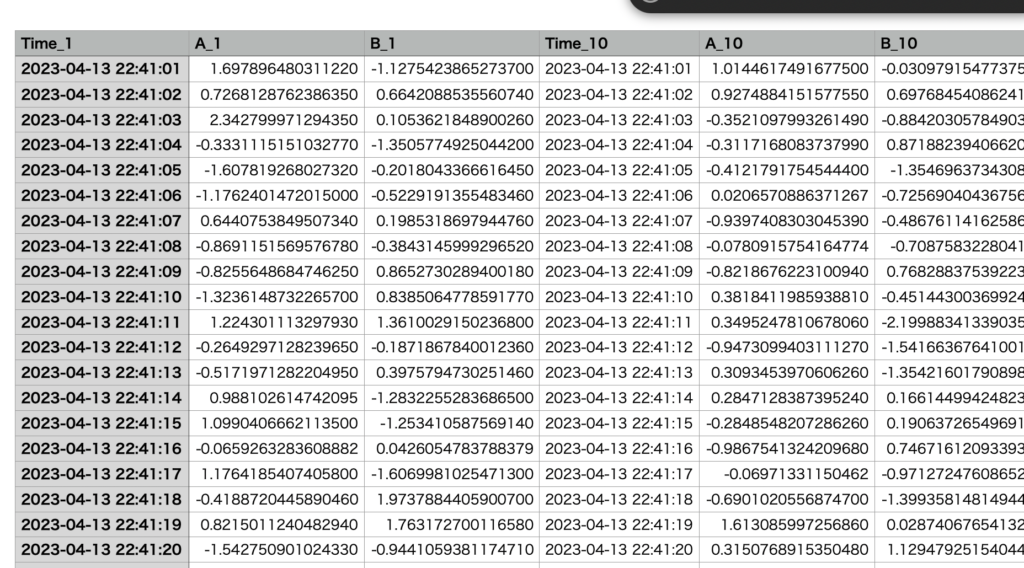
これでどのファイルの列データなのか分かるようになりました。
まとめ
以上が、PythonのPandasを使ったcsvファイルの一括集約のコードの解説です。
フォルダ内の既存のCSVファイルを読み込んで、一つのファイルにまとめる方法をいくつか紹介しました。
この方法をアレンジしてもらえれば好きなようにデータを一瞬ですべて収集して効率的に仕事や研究を進められるかと思います。
このように、Pythonを使ってデータ処理を行うことで、大量のデータを効率的に扱うことができます。特に、Pandasライブラリを使うことで、データフレームという形式でデータを扱うことができ、SQLなどと同様の処理ができるため、大変便利です。
また、Pythonは自由度が高く、豊富なライブラリが用意されているため、様々なデータ処理に応用することができることがわかったのではないかと思います!
さらにPythonのスキルを高めて、効率的に業務を遂行したい、高度なPythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
自分も一度体系的にPythonを学んだことで、一気に日々の業務や人生が変わったと感じています!
以上、ここまでお読みいただき、ありがとうございました!


コメント