概要
こんにちは、すのくろです。
今回は、ランダムにつけられた複数のファイル名をpythonを使って扱いやすい規則正しいファイル名に効率的に行う方法について紹介します。
具体的には以下のイメージです。
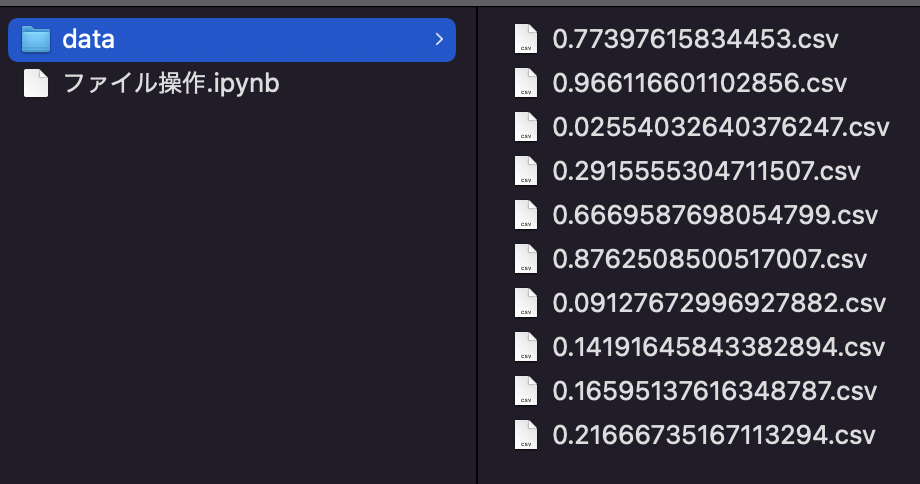
一括変更後↓
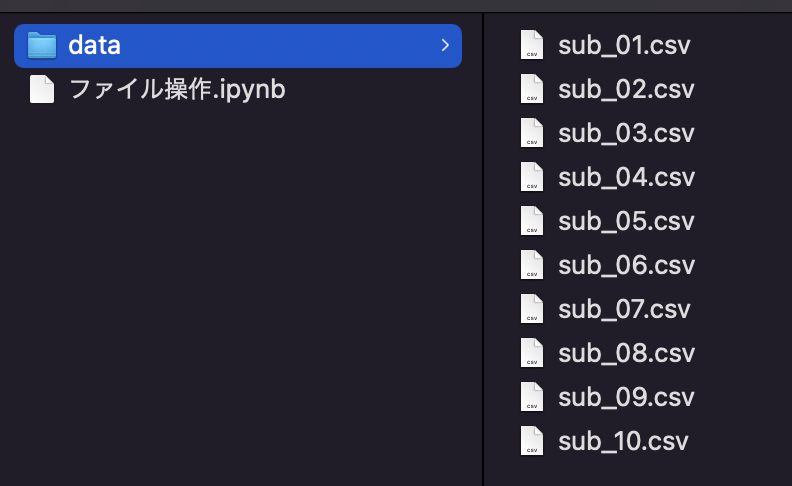
この処理の方法を覚えておくと、他の人からもらったデータや、自分であまり規則的につけられていなかったファイル名を整理して名前を付け直すことができます。
名前が規則的だと、プログラムの処理でfor文などを簡単に行えるようになるため非常に便利です!
それではやっていきましょう!
フォルダの作成
まず初めに、今回操作する用のフォルダを作成しておきましょう。
ファイル変更するプログラムと同じ階層(ディレクトリ)に、手動で新規フォルダを名前をつけて作成しても良いですが、今回はせっかくなのでファイル作成もpython上で行いましょう。
コードは下記です。
import os
# フォルダを作成
os.mkdir("data")「os」というフォルダを操作する系のライブラリをインポートします。
os.mkdir("data")で「data」という空のフォルダを作成します。
ランダムな名前のファイルを作成
次に、フォルダ「data」内に変更する前の不規則なファイルを作っておきます。
今回はランダムな数値名のcsvファイルを10個作成しました。
# フォルダ「data」内にランダムな名前のcsvファイルを作成
import pandas as pd
import numpy as np
for i in range(10):
n = np.random.rand(1)
df = pd.DataFrame()
df.to_csv("data/{}.csv".format(n[0]))コードを実行すると、実際にフォルダ「data」内に10個csvファイルが作成されていることが確認できるかと思います。
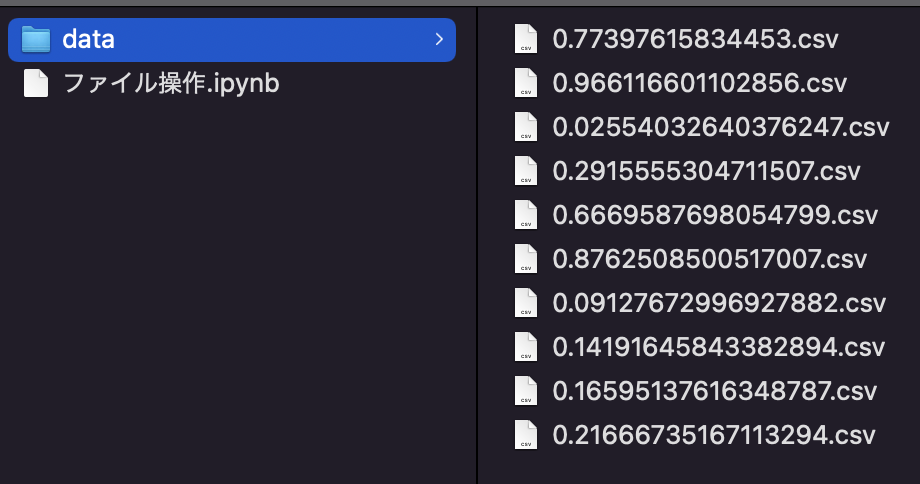
これで下準備は終わりです。
今回はこれらのファイル名を規則的なものに変更します。
フォルダ内のファイル名を取得
まずは処理したいファイルを操作するためにファイル名を全て取得します。
この時には、ライブラリ「glob」を使って行います。
コードは下記になります。
import glob
# 拡張子.csvのファイルを取得する
path = 'data/*.csv'
# csvファイルを取得する
org = glob.glob(path)
print('変更前ファイル名')
print(org)
### 出力結果↓
# 変更前ファイル名
['data/0.46315539099261016.csv', 'data/0.6966701480994029.csv', 'data/0.8194196359395989.csv', 'data/0.9622560409587658.csv', 'data/0.7024907333824142.csv', 'data/0.525993452311608.csv', 'data/0.3946190102709143.csv', 'data/0.9766534727570697.csv', 'data/0.5730129648285217.csv', 'data/0.8937870198530756.csv']少し解説すると、
path = 'data/*.csv'で、data内の「OOOO.csv」というものを指定して、
org = glob.glob(path)で、そのcsvファイル名を所得しています。
文字列を扱うときの*はワイルドカードと言って、なんでも良いという意味です。
変更後のファイル名の作成
次に、不規則なファイル名を規則的な名前に変更するために、
新たなファイル名(扱いやすい規則的なもの)を作成しておきます。
一例は下のコードです。
# 新たなファイル名(扱いやすい規則的なもの)を作成しておく
renames = ["sub_{:0=2}".format(i) for i in range(1, len(org)+1)]
print(renames)
###
# ['sub_01', 'sub_02', 'sub_03', 'sub_04', 'sub_05', 'sub_06', 'sub_07', 'sub_08', 'sub_09', 'sub_10']今回はファイルの数(len(org)値)だけ、sub_01, sub_02,・・・と連番でファイル名を作成しています。
リスト内包表記を使っていますが、リスト内包表記について詳しく知りたい方はこちらの記事も参考にしてください。
新たなファイル名に一括変更
そしてお待ちかねのファイル名の変更です。
コードは下記になります。
# 新たなファイル名に一括変更
for idx, file in enumerate(org):
num = (file[5:-4])
os.rename(file, "data/"+renames[idx] + file[-4:])
print(num + " -> " + renames[idx])
list = glob.glob(path)
print('=============')
print('変更後ファイル名')
print(list)### 出力結果###
0.46315539099261016 -> sub_01
0.6966701480994029 -> sub_02
0.8194196359395989 -> sub_03
0.9622560409587658 -> sub_04
0.7024907333824142 -> sub_05
0.525993452311608 -> sub_06
0.3946190102709143 -> sub_07
0.9766534727570697 -> sub_08
0.5730129648285217 -> sub_09
0.8937870198530756 -> sub_10
=============
変更後ファイル名
['data/sub_06.csv', 'data/sub_07.csv', 'data/sub_05.csv', 'data/sub_10.csv', 'data/sub_04.csv', 'data/sub_01.csv', 'data/sub_03.csv', 'data/sub_02.csv', 'data/sub_09.csv', 'data/sub_08.csv']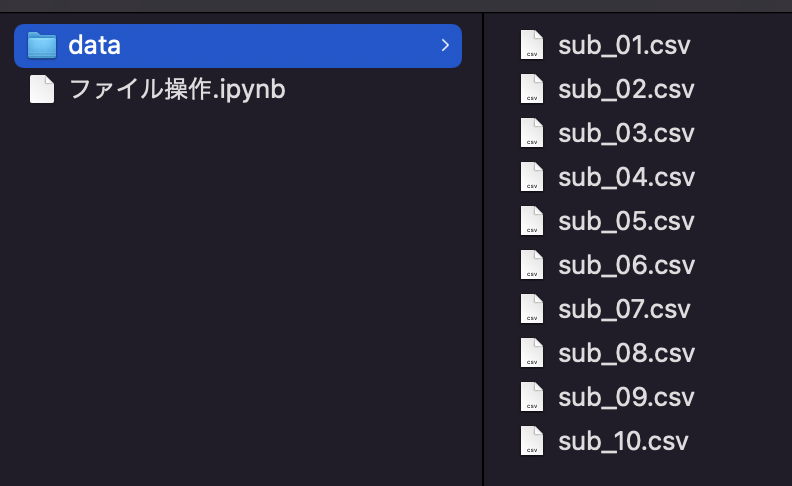
コードは若干長いと感じたかもしれませんが、実際に名前を変更しているコードは、
os.rename(file, "data/"+renames[idx] + file[-4:])になります。もう少しわかりやすく書くと、
os.rename("変更前のファイル名", "変更後のファイル名")という風に指定してあげるだけで変更されます。
この処理をfor文で全てのファイルに対して順番に行っています。
まとめ
今回は、Pythonのosや, glob,を使って不規則なファイル名を一括で変更する方法について説明しました。
手順は小分けにして書いてありますが、必要な部分を最小限にまとめると、
import os
import glob
# 1. フォルダ内の拡張子.csvのファイルを取得する
path = 'data/*.csv'
org = glob.glob(path)
# 2. 新たなファイル名(扱いやすい規則的なもの)を作成しておく
renames = ["sub_{:0=2}".format(i) for i in range(1, len(org)+1)]
# 3. 新たなファイル名に一括変更
for idx, file in enumerate(org):
num = (file[5:-4])
os.rename(file, "data/"+renames[idx] + file[-4:])こんな形です。
皆さんの自分のフォルダでも試してみてください。
その時はファイル名の指定のところの、
num = (file[5:-4])だけは変更が必要ですので、うまく行かない方はスライシングについての記事も参考にしてみてください。
Pythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
以上、ここまでお読みいただき、ありがとうございました!
ここまでお読みいただき、ありがとうございました!

コメント