概要
こんにちは、すのくろです。
今回はPandasによる表データ(データフレーム)から、特定の行や列である条件のものを算出する方法について説明します。
具体的な方法は次のとおりです。
- df[ [True, False]]で、指定行の取り出し
- df[ “A”==OO ] で、特定列で条件に合うデータを取得
- df[ (“A”==OO) & (“B”==OO) ] で、特定列で条件に合うデータを取得(複数条件の場合)
- df[ “A”==OO ].dexcribe()などで、特定条件のデータの代表値の算出
今回の記事を学ぶことで、excel等の表では一手間かかる欲しい条件のデータの取得を、pythonのpandasを用いて簡単かつ直感的にできるようになります!
これによって、その後に好きな条件のデータを取り出して、後の代表値の算出につなげることができるようになります!
それでは、やっていきましょう!
データフレームの作成
初めに今回用いるデータフレーム(df)を作成していきます。
コードは下記の通りです。
data = {
"name": ["Abe", "Ito", "Ueda", "Endo", "Okamura",
"Kato", "Sato", "Tanaka", "Nakamura", "Hamada"],
"age": [22, 30, 32, 20, 40, 11, 23, 45, 56, 46],
"sex": ['male', 'male', 'female', 'male', 'female',
'male', 'female', 'male', 'female', 'female'],
"height": [160, 170, 158, 178, 173, 165, 156, 175, 145, 160],
"weight": [65, 66, 46, 77, 70, 45, 55, 67, 68, 77]
}
df = pd.DataFrame(data)
df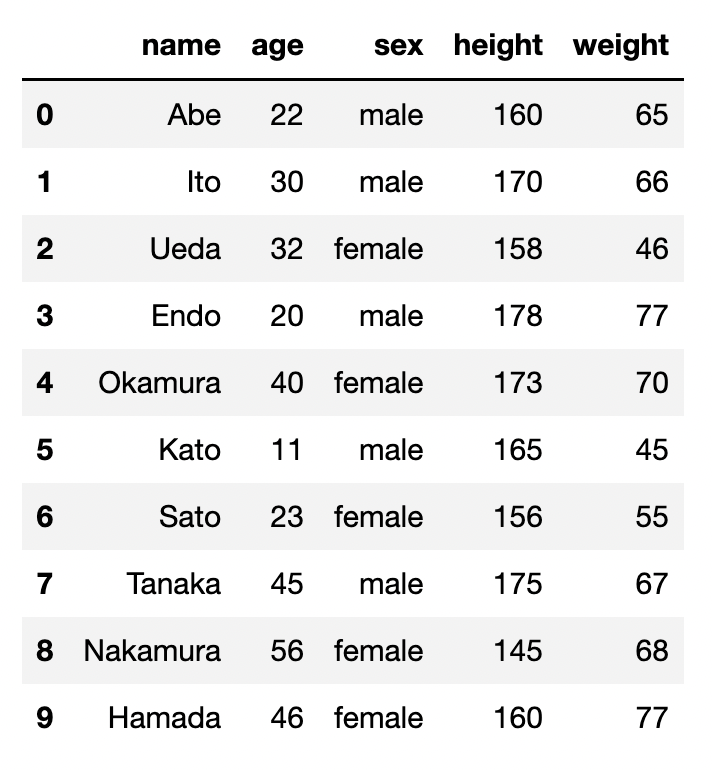
こちらは10名の方の名前、年齢、性別、身長、体重がまとめられた表になっています。
今回はこちらのdfを使って色々と表を操作していきます。
df[ [True, False]]で指定行の取り出し
まず初めに、dfの「フィルタリング」の仕組みについて解説していきます。
dfでは、df[ ]の中にBoolean(True, Falseの型)のリストを入れることで、その時の順番が「True」の場合の行だけを取り出すことができる機能があります。
文字だけだとわかりにくいかもなので、例を以下に示します。
# Booleanのリストでフィルタリング
df_filt = df[[True, False, False, False, False, False, False, False, False, True]]
print(df_filt)
###
# name age sex height weight BMI
# 0 Abe 22 male 160 65 25.390625
# 9 Hamada 46 female 160 77 30.078125このように、df[]の中に、0番目と9番目のみTrueで残りがFalseのリストを入れた場合に、行番号が0, 9のデータだけが出てきました。
この仕組みを先ほどから言っている「フィルタリング」と言います。
フィルタリングを利用することで、条件に合うデータだけを取り出していくことができるわけです。
df[ “A”==OO ] 特定列で条件に合うデータを取得
次に、フィルタリングを利用して、特定の条件を満たす場合の行データのみを取り出す方法について説明します。
原理的には先ほどのTrue, FalseなどのBooleanのリストで条件を得るのと同じです。
下記のコードのように条件式を作ると、列「性別(sex)」でmaleに当てはまる部分のみがTrueとして返ってきます。他のものはFalseになります。
df["sex"] == 'male'
###
# 0 True
# 1 True
# 2 False
# 3 True
# 4 False
# 5 True
# 6 False
# 7 True
# 8 False
# 9 False
# Name: sex, dtype: boolこれで先ほどと同じように、フィルタリングが可能となったわけです。
上の条件式「df[00]==XX」をそのままdf[ ]内部に入れてあげれば良いわけです。
下記がそのコードです。
df_male = df[df["sex"] == "male"]
print(df_male)
###
# name age sex height weight
# 0 Abe 22 male 160 65
# 1 Ito 30 male 170 66
# 3 Endo 20 male 178 77
# 5 Kato 11 male 165 45
# 7 Tanaka 45 male 175 67このフィルタリングでは、列「性別(sex)」が「male」のみのデータを抽出して新たなデータフレーム「df_male」としています。
df[ (“A”==OO) & (“B”==OO) ] 特定列で条件に合うデータを取得(複数条件の場合)
次に複数条件でフィルタリングする場合についてです。
結論としては、
df[ (AAA==XX) & (BBB==OOO) ]のように、df[ ]内に条件をand(&)またはor(|)で繋げていくだけです。
このとき例のように、条件式は()で一つずつまとめてあげないとエラーが起きるのでそこだけ注意が必要です。
また、()で括った方が見た目的にもコードが見やすくて良いと思います。
下記に、複数条件でフィルタリングした例を紹介します。
# 女性で体重が60より上
df[(df["sex"]=="female") & (df["weight"] > 60)]
###
# name age sex height weight BMI
# 4 Okamura 40 female 173 70 23.388687
# 8 Nakamura 56 female 145 68 32.342449
# 9 Hamada 46 female 160 77 30.078125女性かつ、体重が60より上の人のデータだけを取り出してみました。
(晒しているようで、少し申し訳ないです…)
このように、エクセル等の表だと、欲しい条件のデータを取り出すときは一手間入りますが、pythonのpandasを用いれば簡単かつ直感的に好きな条件のデータを取り出すことができます。
df[ “A”==OO ].dexcribe() 特定条件のデータの代表値の算出
最後に、取り出したデータから統計量などの代表値を算出する方法を説明します。
例えばコードは下記になります。
df[df["sex"] == "male"].describe()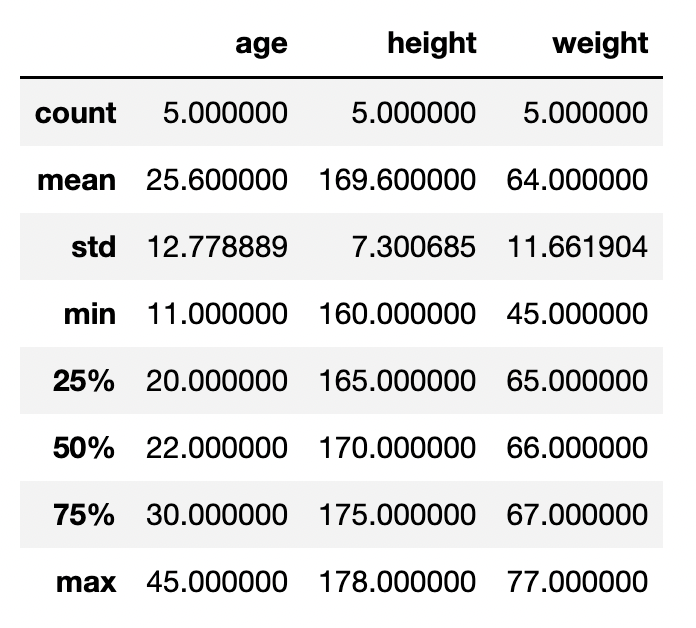
このように、先ほどから作成しているフィルタリング部分のコード(df[ AA==BB])に、.mean()や、.describe()など任意の関数を繋げてあげるだけでOKです。
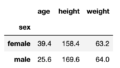
もう一つ例を挙げると、下記が平均値算出の例です。
# 平均値の場合
df[df["sex"] == "male"].mean()
###
# age 25.600000
# height 169.600000
# weight 64.000000
# BMI 22.187392
# dtype: float64これで簡単に求めたい条件を満たすデータだけの統計量等の算出ができます。
まとめ
今回はpandasのデータフレーム(df)で、フィルタリングを行なって、簡単に特定の条件を満たすデータの抽出について説明しました。
具体的な方法は次のとおりでした。
- df[ [True, False]]で、指定行の取り出し
- df[ “A”==OO ] で、特定列で条件に合うデータを取得
- df[ (“A”==OO) & (“B”==OO) ] で、特定列で条件に合うデータを取得(複数条件の場合)
- df[ “A”==OO ].dexcribe()などで、特定条件のデータの代表値の算出
このように、エクセル等の表だと、欲しい条件のデータを取り出すときは一手間入りますが、pythonのpandasを用いれば簡単かつ直感的に好きな条件のデータを取り出して、後の代表値の算出やグラフ作成などにつなげることができます。
ぜひ皆さんもデータの整理、解析には一旦pandasを使ってみることを検討してみてください。
ここまでお読みいただき、ありがとうございました!

コメント