概要
こんにちは、すのくろです。
今回はpandasで扱う表データのデータフレーム(df)の指定箇所の取得方法をまとめて解説します。
今回の内容だけ覚えていただければほとんどの場合で通用すると思います。
内容は以下の通りです。
- 「.loc[]」で指定行の取得
- 「df[“列名”]」で列名から指定列の取得
- 「.iloc[]」で指定範囲の行列の取得
それでは順番に見ていきましょう。
データの下準備
はじめに下準備として、データフレームを作成しておきます。
とりあえず列名が”A”, “B”, “C”, “D”, “E”の10行5列のデータフレームを作成してみます。
import pandas as pd
import numpy as np
x = np.random.randint(1, 100, (10, 5))
cols = ["A", "B", "C", "D", "E"]
df = pd.DataFrame(x, columns=cols)
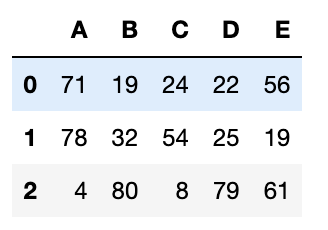
df#### df出力結果(値はランダムなので実行毎に変わる)
A B C D E
0 71 19 24 22 56
1 78 32 54 25 19
2 4 80 8 79 61
3 49 91 61 15 2
4 14 32 19 88 70
5 64 45 99 93 6
6 79 47 76 12 54
7 40 42 21 62 88
8 41 94 41 56 13
9 42 33 31 21 47こちらのdfを使って指定箇所を取得する方法を説明していきます。
「.loc」で指定行の取得
まずは「.loc」で指定行を取得する方法です。
.loc[ ]の[]内に指定したインデックス(行)番号を入れればそのインデックスを全て取得します。
# 「.loc」で、指定行の取得
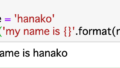
data = df.loc[2]
print(data)
# A 4
# B 80
# C 8
# D 79
# E 61
# Name: 2, dtype: int64.loc[] 指定行の中で、ある列の数の取得
.loc[ 行番号 ][ 列番号 ]で、指定の値を取得できます。
以下の例では、3行目の3列目(「2」は0から数えて3番目)を取得。
# 指定行の中で、ある列の数の取得
data = df.loc[2][2]
print(data)
### 8df[“列名”] 列名指定で指定列の取得
次に列方向のデータの取得について解説していきます。
列方向では、df[ 列名 ] で取得したい列を指定します。
例は下記です。
# 指定列の取得
data = df["A"]
print(data)
###
# 0 71
# 1 78
# 2 4
# 3 49
# 4 14
# 5 64
# 6 79
# 7 40
# 8 41
# 9 42
# Name: A, dtype: int64指定列の中で指定行の取得
列名指定した場合に続けてスライシングで値を指定することで、指定の範囲の数を所得できます。
例1:列名「A」のインデックス番号「1」の値を取得
# 指定列の中で指定行(インデックス)の取得
data = df["A"][1]
print(data)
# 78例2:列名「A」のインデックス番号「1〜3」の範囲を取得
# 指定列の中で指定範囲行(インデックス)の取得
data = df["A"][1:4]
print(data)
# 1 78
# 2 4
# 3 49
# Name: A, dtype: int64複数列の取得
次に、列名指定で複数列を指定したいときの方法です。
列名指定では、df[“A”, “B”, “E”]のように複数指定することはできません。
なので、複数指定する方法について説明します。
まずは、列名指定したい列名をリストで作成します。
そのリストを指定してあげればOKです。
以下が例になります。
# 複数列の取得
col_name = ["A", "B", "E"]
data = df[col_name]
print(data)
####
# A B E
# 0 71 19 56
# 1 78 32 19
# 2 4 80 61
# 3 49 91 2
# 4 14 32 70
# 5 64 45 6
# 6 79 47 54
# 7 40 42 88
# 8 41 94 13
# 9 42 33 47.ilocによるdf指定範囲の取得
最後に「 .iloc[ ] 」を用いた指定範囲の取得方法について説明します。
こちらはNumpyの行列取得方法とほぼ同じ考えでデータフレーム内の値を取得できるので、記述も列名指定よりシンプルになるため便利です。
Numpyでの行列値の取得方法についてはこちらの記事を参考にしてください。
話が少しそれましたが、Pandasでの「 .iloc[ ] 」での使い方を示します。
# 指定行列の値を取得
data = df.iloc[1, 2]
print(data)
### 54# 指定範囲の値を取得(スライシングの利用)
print(df.iloc[1:4, 2:4])
print(data)
###
# C D
# 1 54 25
# 2 8 79
# 3 61 15「 .iloc[ ] 」で、Numpy同様に、簡単にdfの値を取得できることがわかったかと思います。
まとめ
今回はpandasで扱う表データのデータフレーム(df)の指定箇所の取得方法をまとめて解説しました。
- 「.loc[]」で指定行の取得可能
- df[“列名”]で指定列の取得可能
- 複数列指定の場合は、リストで列名を作成
- 「.iloc[]」でNumpy同様に指定範囲の行列の取得可能
今回の内容だけ覚えておけば表のデータ量が多くなっても基本的には自在にデータを取得してデータ分析などに対応できるかと思います。ぜひ今回の内容を使っていただけると幸いです。
ここまでお読みいただき、ありがとうございました!

コメント