こんにちは、すのくろです。
今回はPythonのDiffuserモデルを使ってテキストから画像生成を行うプログラムコードを作成したので、紹介したいと思います。
特に環境構築や他のウェブサイトで登録などをする必要もありません。
下記コードをGoogle Colabに貼り付けれて、テキスト部分を好きな言葉に変えるだけで実現できます!
【完成版コード】
import torch
from diffusers import StableDiffusionPipeline
#下のpromptの中に表示させたい画像の文章を入れる
prompt = "OOOOOOOOO"
pipe = StableDiffusionPipeline.from_pretrained('CompVis/stable-diffusion-v1-4', revision='fp16')
pipe = pipe.to('cuda')
generator = torch.Generator('cuda').manual_seed(42)
image = pipe(prompt, guidance_scale=7.5, generator=generator, height=512, width=512,
num_inference_steps=50,).images[0]
image.save(f'{prompt}.png')
image以下、手順やコードの解説していきます!
手順
Pythonの画像生成における新たな手法として、Diffuserモデルを使用した画像生成があります。
Diffuserは、安定化した拡散プロセスを利用して画像を生成するためのモデルです。以下のコードを使って、具体的な実装方法を紹介します。
Google Colabの用意
- WebブラウザでGoogle Colabのホームページ(https://colab.research.google.com)にアクセスします。
- “新しいノートブックを作成” をクリックします。
- 新しいノートブックが開かれます。ノートブックには、コードを入力し、実行することができます。
- ノートブックの上部メニューには、実行、セルの追加や削除、ファイルのアップロードなどの操作があります。
Google ColabでGPUを使う設定
今回のコードを実行するにあたり、環境によっては途中で処理が止まってしまう場合があります。
なので、Google ColabのGPUを使用していきます。
- ノートブック上部メニューの “ランタイム” をクリックします。
- “ランタイムのタイプを変更” を選択します。
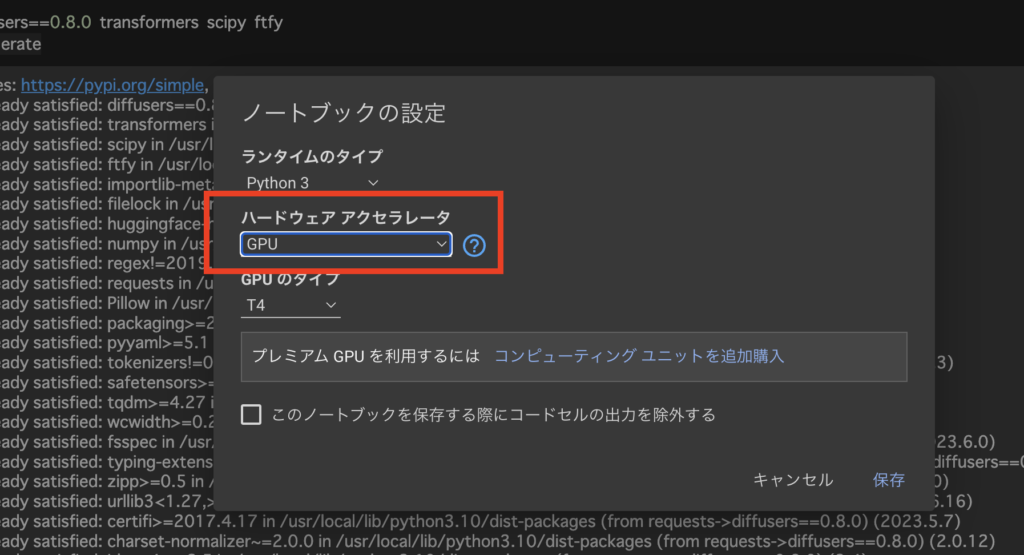
3. “ハードウェア アクセラレータ” のセクションで、”GPU” を選択します。
4. “保存” をクリックして変更を適用します。
これで、Google ColabでGPUを利用する準備が整いました。
GPUの使用には制限がある場合がありますが、一般的には無料で利用できます。
コードを実行する際に、GPUを活用して高速化や大規模なデータ処理を行うことができます。
なお、Google Colabでは一定の制限があるため、長時間の実行や大規模なデータ処理には注意が必要です。また、セッションが一定時間経つと切断される場合もあるため、定期的に保存することをおすすめします。
必要なパッケージのインストール
ここまでで下準備は整いました。
ここからはGoogle Colab上で紹介するコードを打ち込んでいくだけです。
まず、必要なパッケージをインストールします。
!pip install diffusers==0.8.0 transformers scipy ftfydiffusers、transformers、scipy、ftfyなどのライブラリが必要です。
必要なモジュールをインポート
次に、必要なモジュールをインポートします。
torchとdiffusersからStableDiffusionPipelineをインポートします。
import torch
from diffusers import StableDiffusionPipelineprompt変数に生成画像のテキスト入力
次に、表示させたい画像の文章を指定します。
prompt変数に表示させたいテキストを入力します。例えば、今回は、’dog drown by Vincent van Gogh’としてみました。「ゴッホが描いた犬の顔」です。
prompt = 'dog drown by Vincent van Gogh'モデルの実行
あとは下記のコードでモデルを実行して先ほど指定したテキストを表現した画像を生成します。
pipe = StableDiffusionPipeline.from_pretrained('CompVis/stable-diffusion-v1-4', revision='fp16')
pipe = pipe.to('cuda')
generator = torch.Generator('cuda').manual_seed(42)
image = pipe(prompt, guidance_scale=7.5, generator=generator, height=512, width=512,
num_inference_steps=100).images[0]
image.save(f'{prompt}.png')
imagepipeの引数について説明しておきます。
- height=512, width=512:画像の縦横幅
- num_inference_steps=100:学習のステップ数(デフォルト50)
画像の保存・表示
最後に、画像をprompt名で保存しておきます。
あとはColab上にコードの実行が終わったら画像を表示させてます。
image.save(f'{prompt}.png')
image今回作成した画像
prompt = ‘dog drown by Vincent van Gogh’
結果

ゴッホの「ひまわり」のタッチで犬の絵が描けてますね。あんまり知りませんが。
まとめ
以上が、Diffuserモデルを使った画像生成の手法の解説です。
この手法を使って、興味深い画像生成の実験やプロジェクトに挑戦してみてください!
今回の例以外にも、Pythonは自由度が高く、豊富なライブラリがまだまだ用意されているため、様々なデータ処理や効率化に応用することができます!
さらにPythonのスキルを高めて、効率的に業務を行いたい、高度なPythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
自分も一度体系的にPythonを学んだことで、一気に日々の業務や人生が変わったと感じています!
以上、ここまでお読みいただき、ありがとうございました!


コメント