概要
こんにちは、すのくろです。
今回は、iteritems()やiterrows()を使ってデータをfor文で簡単に回す方法について解説します。
これらの関数は初めは分かりにくい部分があるかもですが、慣れればすごい使い勝手が良いので、ぜひ覚えて頂けると幸いです。
以下、本記事の内容です。
- .iteritems()で1列ずつ取り出す
- .iterrows()で1行づつ取り出す
- .itertuples()で1行づつ取り出す
- itertuples()を使ったデータ分析の例
それでは早速やっていきましょう!
下準備
初めにデータを扱う下準備として、ライブラリのインポートをします。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt %matplotlib inline続いて、今回扱うデータを作成します。
データは、10人の名前、年齢、性別、身長、体重が列で並べられたデータベースとします。
# データの用意 data = {
"name": ["Abe", "Ito", "Ueda", "Endo", "Okamura",
"Kato", "Sato", "Tanaka", "Nakamura", "Hamada"],
"age": [22, 30, 32, 20, 40, 11, 23, 45, 56, 46],
"sex": ['male', 'male', 'female', 'male', 'female',
'male', 'female', 'male', 'female', 'female'],
"height": [160, 170, 158, 178, 173, 165, 156, 175, 145, 160],
"weight": [65, 66, 46, 77, 70, 45, 55, 67, 68, 77]
}
df = pd.DataFrame(data)
df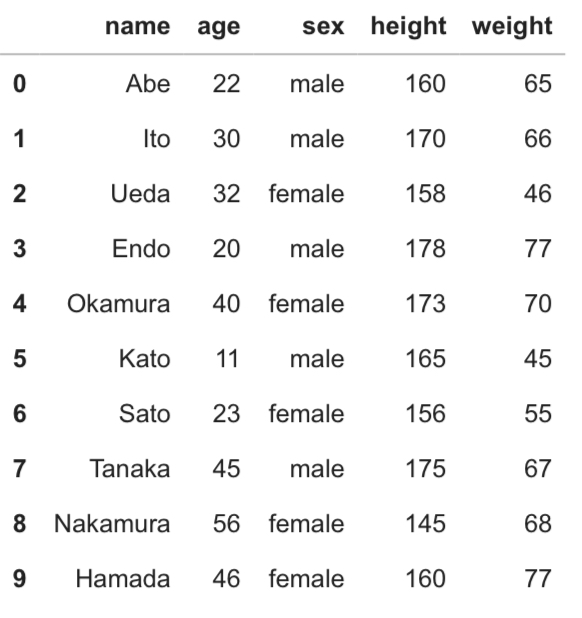
上記のデータを使って解説していきたいと思います。
.iteritems()で1列ずつ取り出す
まずはiteritems()について解説です。
iteritems()メソッドは、コラム名(列名)とその列のデータ(pandas.Series型)のタプル(列名, データ)を1列ずつ取得するメソッドになります。
まずは下記コードで一列ずつデータをプリントする例を示します。
# 1列ずつ取り出す時
for col, item in df.iteritems():
print("--------col={}----------".format(col))
print(item)
####出力結果↓
--------col=name----------
0 Abe
1 Ito
2 Ueda
3 Endo
4 Okamura
5 Kato
6 Sato
7 Tanaka
8 Nakamura
9 Hamada
Name: name, dtype: object
--------col=age----------
0 22
1 30
2 32
3 20
4 40
5 11
6 23
7 45
8 56
9 46
Name: age, dtype: int64
--------col=sex----------
(以下略)このように、一ループごとに列のデータを出力していることが分かります。
列内の各要素データの値は、pandas.Seriesのインデックス名などを指定することで取り出せます。
下記コードがその例です。
# 1列ずつ0行目(列名)を取り出す時
for col, item in df.iteritems():
print(item[0])
###
Abe
22
male
160
65この様に、index=0で固定してその時の列を順番に出力しています。
全体ではなく、欲しいインデックス番号が決まっている場合はiteritems()と[行番号]指定で取り出せることがわかったかと思います。
.iterrows()で1行づつ取り出す
次に、.iterrows()で1行づつ取り出す方法についてです。
iterrows()メソッドを使うと、インデックス名(行名)とその行のデータ(pandas.Series型)のタプル(行番号, データ)を1行ずつ取得できます。
下記が例です。
# 1行ずつ取り出す時
for index, row in df.iterrows():
print("--------index={}----------".format(index))
print(row)
###
--------index=0----------
name Abe
age 22
sex male
height 160
weight 65
Name: 0, dtype: object
--------index=1----------
name Ito
age 30
sex male
height 170
weight 66
Name: 1, dtype: object
--------index=2----------
name Ueda
age 32
sex female
(以下略)今回の場合、変数indexに行番号、rowにその行の全列のデータが入り、1行ごとに出力されています。
row[0]のように列名を指定してあげれば、その固定した列名を1行目から順番に回すこともできます。
下記がその例です。
# 1行ずつ指定列を取り出す時
for index, row in df.iterrows():
print("--------index={}----------".format(index))
print(row[1])
#####出力結果
--------index=0----------
22
--------index=1----------
30
--------index=2----------
32
--------index=3----------
20
--------index=4----------
40
--------index=5----------
11
--------index=6----------
23
--------index=7----------
45
--------index=8----------
56
--------index=9----------
46.itertuples()で1行づつ取り出す
次に、itertuples()について解説します。
itertuples()はiterrows()とほぼ同じ様に使うことができます。
各インデックスごとにデータの要素をタプル( ) まとめて出力します。
実際の様子を見た方が早いと思いますので、コードを示します。
# 1行ずつ指定列を取り出す時 (itertuples)
# itertuples()のほうが高速
for row in df.itertuples():
print(row)
#####
Pandas(Index=0, name='Abe', age=22, sex='male', height=160, weight=65)
Pandas(Index=1, name='Ito', age=30, sex='male', height=170, weight=66)
Pandas(Index=2, name='Ueda', age=32, sex='female', height=158, weight=46)
Pandas(Index=3, name='Endo', age=20, sex='male', height=178, weight=77)
Pandas(Index=4, name='Okamura', age=40, sex='female', height=173, weight=70)
Pandas(Index=5, name='Kato', age=11, sex='male', height=165, weight=45)
Pandas(Index=6, name='Sato', age=23, sex='female', height=156, weight=55)
Pandas(Index=7, name='Tanaka', age=45, sex='male', height=175, weight=67)
Pandas(Index=8, name='Nakamura', age=56, sex='female', height=145, weight=68)
Pandas(Index=9, name='Hamada', age=46, sex='female', height=160, weight=77)itertuples()の返り値rowに対して、
row[列番号]や、row.列名
とすることでその指定列のみを回すこともできます。
for row in df.itertuples():
print("------")
print(row[2])
print(row.age)
print("------")
#####
------
22
22
------
------
30
30
------
------
32
32
------
------
20
20
------
------
40
40
------
------
(以下略)itertuples()を使ったデータ分析の例
最後にitertuples()を使った実際のデータ分析の例を紹介します。
まずはデータの準備です。上記で使ってたものと同じデータフレームです。
# データの用意
data = {
"name": ["Abe", "Ito", "Ueda", "Endo", "Okamura",
"Kato", "Sato", "Tanaka", "Nakamura", "Hamada"],
"age": [22, 30, 32, 20, 40, 11, 23, 45, 56, 46],
"sex": ['male', 'male', 'female', 'male', 'female',
'male', 'female', 'male', 'female', 'female'],
"height": [160, 170, 158, 178, 173, 165, 156, 175, 145, 160],
"weight": [65, 66, 46, 77, 70, 45, 55, 67, 68, 77]
}
df = pd.DataFrame(data)このデータから、「身長」と「体重」の散布図を作成します。
plt.scatter("height", "weight", data=df)
plt.xlabel("height")
plt.ylabel("weight")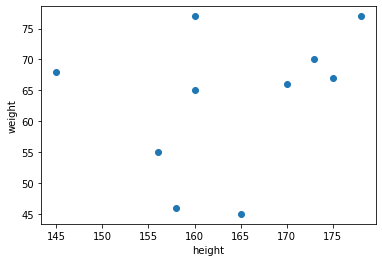
ここで、散布図のマーカーに名前をつけたい時に、itertuples()を活用してみます。
plt.scatter("height", "weight", data=df)
plt.xlabel("height")
plt.ylabel("weight")
for row in df.itertuples():
plt.annotate(row.name, (row.height, row.weight))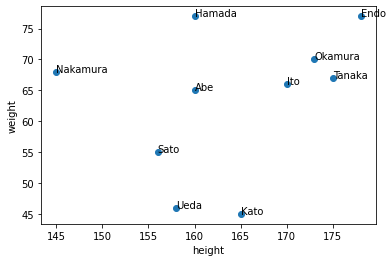
for row in df.itertuples():
plt.annotate(row.name, (row.height, row.weight))で、各行のnameをその行の(height値、weight値)の座標にplt.annotate()でプロットしています。
この様に、各行のデータを対応させて使い、for分で回す時にはitertuples()やiterrows()が便利です。
まとめ
今回は、pandasで作成したデータフレームの行や列のデータをセットで回す手段であるiteritems(), iterrows(), itertuples()について解説しました。
これらのメソッドを学ぶことで、pandasの行列操作がやりやすくなるかと思いますので、参考になれば嬉しいです。
Pythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
以上、ここまでお読みいただき、ありがとうございました!


コメント