概要
こんにちは、すのくろです。
今回は、データ分析に用いる土台となる表データを作成・操作する方法について記載します。
今回の記事を読むことで以下の点が理解できます。
- ライブラリpandasを用いた表データの作成
- 表データの行や列の操作(順番入れ替え・列データの更新)
- 行列名の変更
- 表データの保存
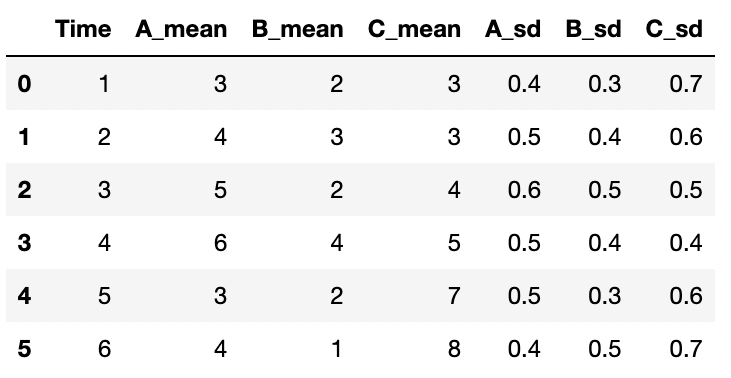
以下のようなものが最終アウトプットの例です。
それでは解説していきます!
使用するライブラリ(Pandas & Numpy)
はじめに、データの操作・計算やグラフ描画をしていくために、必要なモジュール(関数を使うためのパックみたいなもの)をインポートします。
コードは↓になります。
import pandas as pd
import numpy as np- pandas:表データを扱うことに特化したライブラリ
- numpy:行列を扱うことに特化したライブラリ
このコードの書き方はどんな時でも同じなので、プログラムを新たに作成するときは常にこのコードをコピペして使ってあげれば良いと思います。
項目のリストを表にまとめる
それでは、早速Pandasを使って、表を使っていきましょう!
例えば、リストの変数a, b, cをまとめて表にしたいという場合は、下記コードになります。
a = [3, 4, 5, 6, 3, 4]
b = [2, 3, 2, 4, 2, 1]
c = [3, 3, 4, 5, 7, 8]
df = pd.DataFrame([a, b, c])
df出力結果↓
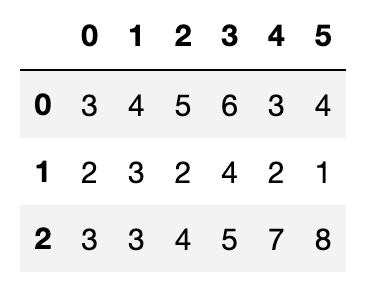
このように、変数a, b, cを3行にまとめて、表にすることができました。
表の行と列の入れ替え(転置)
↑で作成した表だと、項目(a, b, c)が行方向に並んでいます。
一般的に表データを扱うときは項目が列ごとにまとまっていた方が扱いやすいです。
なので、作成したデータフレーム(df:表)の行と列を入れ替えてみます。
やり方はとても簡単で、「.T」をデータフレームの変数に付けるだけです。
(Tはtranspose(転置)の頭文字です。)
# 表の転置(行と列の入れ替え)
df_t = df.T
df_t出力結果↓

表の行名・列名の変更
表の基本的な読み込み方と、その転置を行いましたが、デフォルトだと行列名がただの数字の連番になっているので、意味がわかりやすいように行列名を変更してみましょう。
コードは↓です。
①列名の変更
# 列名を変更
df_t.columns = ["A", "B", "C"]
df_t出力結果↓

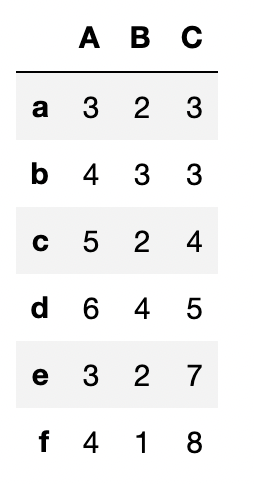
②行名の変更
# 行名を変更(あまりしない)
idx=["a", "b", "c", "d", "e", "f"]
# idx = np.arange(1,7)
df_t.index = idx
df_t出力結果↓
これらの処理は何度でも行えるので、上書き可能です。
また、今回は行名も変更しましたが、行は数字の連番を振るだけの方が扱いやすいと思います。
なので、あまり行名は変更する機会はないかもです。
表に新たなデータ列の追加
続いて、既存のデータフレームに新たに項目を追加したい場合に、データ列を追加する方法の説明です。
例えば、今回は、「時間」列のデータを追加したいとします。
その場合、↓のコードで実現できます。
# 新たな列を追加
# t = [1, 2, 3, 4, 5, 6]
t = np.arange(1, 7)
df_t["Time"] = t
df_t出力結果↓

コードの解説です。
はじめに「時間」データを今回は変数「t」とします。
tはnumpyの関数「np.arange()」で1〜6までの整数の連番を作成しました。
この時間データ列をデータフレームdf_tに追加します。
追加方法は、
df_t[“Time”] = t
になります。
これは、df_tの列名がTimeというところのデータを、「t」のデータに変更して下さい。という意味合いがあります。
ただし、元々df_tには列名「Time」が存在していないので、新たに表の右端に作成されるといった出力になってます。
なので、もしもう一度、↓のコードで、df_t[“Time”] = t2 とすると「Time」列が上書きされます。
# 列の更新
# t = [1, 2, 3, 4, 5, 6]
t2 = np.arange(8, 14)
df_t["Time"] = t2
df_t出力結果↓
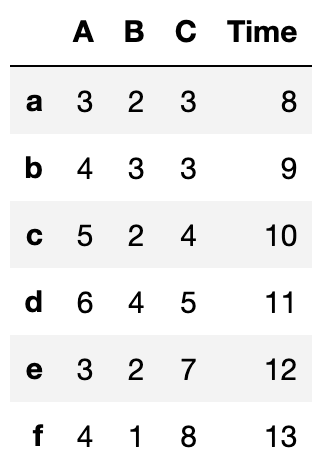
表データの操作において、df[“〇〇”] = ××× は結構使うので覚えていただけると幸いです。
ひとまず、これで新たな列の追加や既存列の更新ができました。
列の順番を変更
新たに列を追加、変更した場合、表の列の並びを変更したい時があります。
そんな時には、
.reindex(columns=[“AAA”, “BBB”, “CCC”])などで
任意の順番を指定してあげると、その通りに列が並び替えられます。
また、列変更のもう一つの方法として、
df[[“AAA”, “BBB”, “CCC”]]
のように描く方法もあります。
今回の表の場合では、「Time」列を前に持っていきたいので、↓のコードのようになります。
# 列の順番を変更
df_t = df_t.reindex(columns=["Time", "A", "B", "C"])
# df_t = df_t[["Time", "A", "B", "C"]] でも可能
df_t出力結果↓
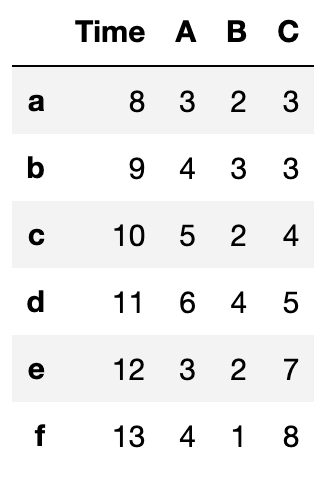
これで各データ「A、B、C」の前に「Time」列が来ていて見栄えがいいです。笑
関数一発で各リストから表を作成
ここまで解説してきた流れは、↓の通りです。
- 「df = pd.DataFrame()」で複数リスト⇨表dfに変更
- 「df.T」で表の行列入れ替え
- 「df.columns」で列名を変更
- 「df.index」で行名を変更
- 「df[“OO”]=****」で新たな列の追加
- 「df.reindex(columns=[“OOO”, “OOO”, “OOO”])」で列の順番を変更
ただ、もし作りたい表の最終イメージが決まっているのであれば、最初の表作成時の
「df = pd.DataFrame()」である程度完成形に近い表を作成できます。
# 関数一発で各リストから表を作成する場合
df = pd.DataFrame({"Time": t, "A": a, "B": b, "C": c}, index=idx)
df出力結果↓
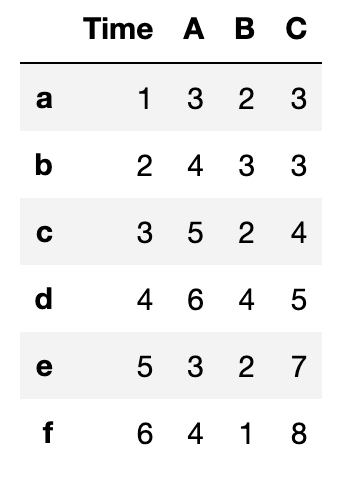
このように、pd.DataFrame()にはかなり多くの引数が設定されているので、
それらを活用することで、質の高い表を手軽に作成可能です。
実際に使えそうな表の例
最後に復習として、表の作成で実際に使うような表の例を示します。
- t:時間
- 各パラメータ a, b, cの平均値
- 各パラメータ a, b, cの標準偏差
をまとめた表を作成したいときは↓のようになります。
# 実戦で使う例
# 平均値
a = [3, 4, 5, 6, 3, 4]
b = [2, 3, 2, 4, 2, 1]
c = [3, 3, 4, 5, 7, 8]
# 標準偏差
aa = [0.4, 0.5, 0.6, 0.5, 0.5, 0.4]
bb = [0.3, 0.4, 0.5, 0.4, 0.3, 0.5]
cc = [0.7, 0.6, 0.5, 0.4, 0.6, 0.7]
# 時間
t = np.arange(1, 7)
df = pd.DataFrame({"Time": t, "A_mean": a, "B_mean": b, "C_mean": c, "A_sd": aa, "B_sd": bb, "C_sd": cc})
dfこれらのグラフを作成できると、他の記事で紹介した棒グラフや折れ線グラフ、箱ひげグラフ等をdfから手軽に作成可能です!
csvデータとして表を保存
最後に作成した表の保存方法です。
↓コードで、csvファイルとして出力可能です。
# 「df_data.csv」という名前のCSV ファイル として保存(出力)
df.to_csv("df_data.csv") まとめ
今回は、データ分析に用いる土台となる表データをライブラリpandasを用いて作成・操作する方法について解説しました。
- 「df = pd.DataFrame()」で複数リスト⇨表dfに変更
- 「df.T」で表の行列入れ替え
- 「df.columns」で列名を変更
- 「df.index」で行名を変更
- 「df[“OO”]=****」で新たな列の追加
- 「df.reindex(columns=[“OOO”, “OOO”, “OOO”])」で列の順番を変更
- 「.to_csv()」で表データの保存
ここまでお読みいただきありがとうございました!


コメント