
こんにちは、すのくろです。
画像内のテキストを自動的に読み取るテキスト認識は、PythonとOCR(光学文字認識)の組み合わせによって非常に容易に実現できます。
この記事では、Pythonの「Tesseract」を使用して、画像のテキストを読み取る方法について初期の状態から必要なもののインストール方法なども含めて詳しく解説します。
[使用環境]
- Mac OS 13.4.1 (Apple M1チップ)
- Anaconda3
- Python3.9
Pythonによる画像のテキスト認識

画像のテキスト認識とは
画像のテキスト認識とは、画像内に含まれるテキスト情報を検出し、文字列として抽出するプロセスです。
例えば、スキャンされた文書や写真内のテキストを自動的に読み取ることができます。
Pythonの強力なOCRライブラリを活用することで、高い精度でテキスト認識を実現できます。
PythonとOCR(光学文字認識)の組み合わせのパワフルさ
Pythonは、豊富なOCRライブラリと組み合わせることで、テキスト認識のタスクを効果的に解決するための優れたツールです。
特に、TesseractというオープンソースのOCRエンジンは、高い精度と幅広い言語のサポートを提供しています。
今回はこのPythonのTesseractを使用して、画像のテキスト認識を行っていきます!
必要なライブラリのインストール
まずは、必要なライブラリをインストールしましょう。
PythonのpytesseractライブラリとTesseract OCRエンジンを使用します!
Homebrewをインストール
Macの方で、まだ『Homebrew』をインストールしていないという場合は、先に『Homebrew』を『ターミナル』からインストールしてください。
(もし既にインストールしている方はこちらのセクションは不要です。)
下記のコマンドをターミナルで実行して、Homebrewをインストールします。
/bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
そうすると赤枠のように、パスワードの入力を求めらるので、MacBookのログインパスワードを入力してエンターを押します。
このとき、自分は画面上にパスワードが表示されてなくておかしいと思いましたが、一応入力はされているみたいなので、そこは気にせずパスワードを入力してエンターを押してください。
あとは画面でもう一度Enterキーを押してインストールすることを求められるので、Enterキーを押して実行してしばらく待ちます。
これでインストール完了(Installation successful)と出ればOKです。
自分はここでM1チップを使用しているとうまくHomebrewがインストールできないようでして、下記のような画面が出ました。
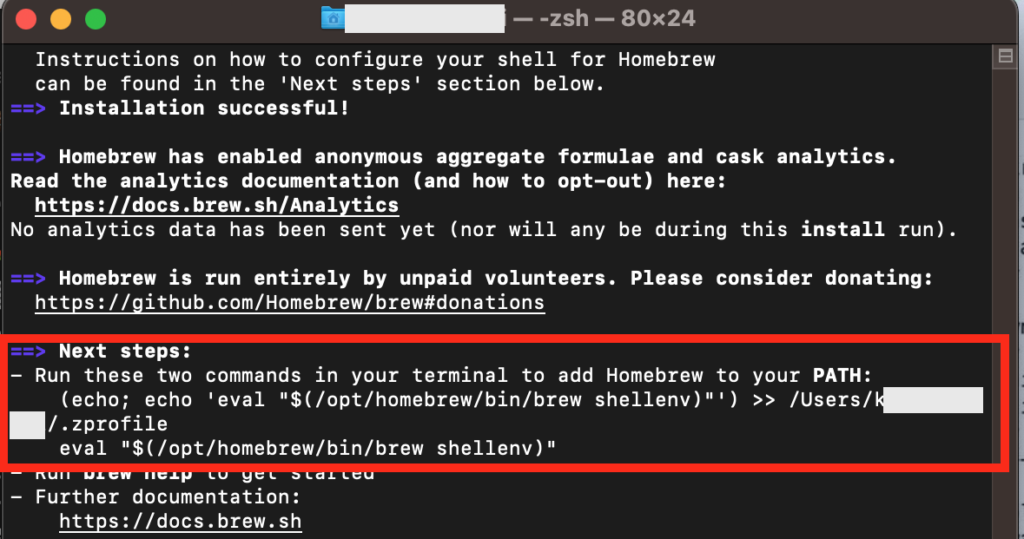
この場合は、赤枠の「Next Step」で示されている2つのコードを実行します。
これでHomebrewが無事にインストールできました!
pytesseractをインストール
以下のコマンドをターミナルで実行してインストールします。
pip install pytesseract
brew install tesseract # macOSの場合pytesseractをインストール
デフォルトでは、pytesseractは英語の認識設定なので、もし、画像で認識させたい言語が日本語の場合は下記のコードもターミナルで実行が必要です。
brew install tesseract-lang上記コード実行後、自分はMacのM1チップを使っているせいか、下記のエラーが出ました。
M1チップは「Rosetta」というものが使われていることが原因のようでした。
Error: Cannot install under Rosetta 2 in ARM default prefix (/opt/homebrew)!
To rerun under ARM use:
arch -arm64 brew install …
To install under x86_64, install Homebrew into /usr/local.なので、指示に従い、下記で実行することで解決しました。
arch -arm64 brew install tesseract-lang同じようなエラーが出た場合は、この方法を試してください。
Tesseractで画像からテキストを読み取る手順と実際のコード
画像からテキストを読み取る具体的なコード例は、以下の通りです。
import pytesseract
from PIL import Image
# 画像ファイルのパス
image_path = '画像ファイルのパス'
# 画像を開く
image = Image.open(image_path)
# 画像のテキストを読み取る
text = pytesseract.image_to_string(image, lang='jpn')
# 読み取られたテキストを出力する
print(text)
# ファイルにテキストを書き込む
output_file = '{}-text-jp.txt'.format(image_path[:-4])
with open(output_file, 'w', encoding='utf-8') as file:
file.write(text)手順の詳細を解説していきます。
画像の読み込み
PythonのPillow(PIL)ライブラリを使用して、画像ファイルを開きます。
# 画像ファイルのパス
image_path = '画像ファイルのパス'
# 画像を開く
image = Image.open(image_path)テキスト認識の処理
pytesseractライブラリを使用して、画像内のテキストを認識します。
# 画像のテキストを読み取る
text = pytesseract.image_to_string(image)
結果の取得と表示
認識結果を取得し、テキストとして表示します。
# 読み取られたテキストを出力する
print(text))また、出力したテキストを下記のコードで「.txt」ファイルとして保存しています。
# ファイルにテキストを書き込む
output_file = '{}-text-jp.txt'.format(image_path[:-4])
with open(output_file, 'w', encoding='utf-8') as file:
file.write(text)テキストファイルはプログラムと同じフォルダ内に「(画像名)-text-jp.txt」として作成されます。
これでより汎用的に認識したテキストを扱うことができます。
Tesseractによるテキスト認識の結果
今回このpプログラムコードを実行した例を紹介しておきます。
下記の画像を読み込んだ結果

結果
プログラミングを使った効率化や快適な時間を増やすためのお役立ちサイト
Free Cormfortable Life
Pythonで画像のテキストを読み取る方法 - 実践的なテキスト認識の手法
トノ f B! ウ ドリ 馬
Twitter Facebook はてブ Pocket LINE コピー
〇 2023.07.15
こんにちは、すのくろです。
画像内のテキストを自動的に読み取るテキスト認識は、PytnonとOCR (光学文字認識) の組み合わせによ
って非常に容易に実現できます。
この記事では、Pythonを使用して画像のテキストを読み取る方法について詳しく解説します。
目 次 じる]
1. Pythonによる画像のテキスト認
1. 画像のテキスト認識とは
2. PythonとOCR (光学文字認識) の組み合わせのパワフルさ
2. 必要なライブラリのインストール
3. 画像からテキストを読み取る手順と実際のコード
1. 画像の読み込み上のような認識結果になりました。
ある程度は認識できていますが、100%ではないですね。
Tesseractでテキスト認識の精度を向上させる方法
テキスト認識の精度を向上させるためには、以下の方法があります。
画像の前処理
画像の明るさやコントラストの調整、ノイズの除去、シャープネスの補正など、さまざまな画像処理技術を使って画像を最適化することができます。
これにより、テキスト部分が明確になり、認識エンジンが正確にテキストを抽出できるようになりやすいです。
言語や文字セットの指定
識対象の言語や文字セットを明示的に指定することで、認識結果の精度を向上させることができます。
Tesseractは多言語のサポートを提供しており、pytesseractを使用して言語オプションを設定することができます。
適切な言語を指定することで、特定の言語のテキストをより正確に認識することができます。
パラメータの調整
Tesseractの認識エンジンには、さまざまなパラメータがあります。
これらのパラメータを調整することで、最適な結果を得ることができます。
たとえば、文字の大きさやフォント、文字の間隔、行の間隔などのパラメータを微調整することで、特定の画像に最適な設定を見つけることができます。
パラメータの調整には試行錯誤が必要な場合がありますが、正確なテキスト認識のために重要です。
まとめ
PythonのTesseractを使用して画像のテキストを読み取る方法について解説しました。
Pythonの強力なOCRライブラリとTesseract OCRエンジンの組み合わせは、テキスト認識タスクを効率的に解決するための優れたツールです。
ほとんどの画像内の文字は読み取ってくれました!特に、シンプルな文章だけであればかなり高い精度で読み取ってくれます。
何段にも分かれているような文章や囲みが多いものに関してはそこそこの精度でした。
ぜひ、 今回紹介した手法を活用して、画像内のテキストを自動的に抽出するアプリケーションを開発してみてください!
参考書籍
今回の例以外にも、Pythonは自由度が高く、豊富なライブラリがまだまだ用意されているため、様々なデータ処理や効率化に応用することができます!
さらにPythonのスキルを高めて、効率的に業務を行いたい、高度なPythonを中心としたプログラミングをより体系的に学びたいと言う方向けに、おすすめのオンラインスクールを2つ厳選して紹介していますので、こちらもよければご覧ください!
自分も一度体系的にPythonを学んだことで、一気に日々の業務や人生が変わったと感じています!
以上、ここまでお読みいただき、ありがとうございました!

-120x68.jpeg)
コメント